Description: Text document
|
| From: | Neo Jia |
| Subject: | Re: [Qemu-devel] VFIO based vGPU(was Re: [Announcement] 2015-Q3 release of XenGT - a Mediated ...) |
| Date: | Tue, 26 Jan 2016 01:48:19 -0800 |
| User-agent: | Mutt/1.5.24 (2015-08-30) |
On Mon, Jan 25, 2016 at 09:45:14PM +0000, Tian, Kevin wrote:
> > From: Alex Williamson [mailto:address@hidden
> > Sent: Tuesday, January 26, 2016 5:30 AM
> >
> > [cc +Neo @Nvidia]
> >
> > Hi Jike,
> >
> > On Mon, 2016-01-25 at 19:34 +0800, Jike Song wrote:
> > > On 01/20/2016 05:05 PM, Tian, Kevin wrote:
> > > > I would expect we can spell out next level tasks toward above
> > > > direction, upon which Alex can easily judge whether there are
> > > > some common VFIO framework changes that he can help :-)
> > >
> > > Hi Alex,
> > >
> > > Here is a draft task list after a short discussion w/ Kevin,
> > > would you please have a look?
> > >
> > > Bus Driver
> > >
> > > { in i915/vgt/xxx.c }
> > >
> > > - define a subset of vfio_pci interfaces
> > > - selective pass-through (say aperture)
> > > - trap MMIO: interface w/ QEMU
> >
> > What's included in the subset? Certainly the bus reset ioctls really
> > don't apply, but you'll need to support the full device interface,
> > right? That includes the region info ioctl and access through the vfio
> > device file descriptor as well as the interrupt info and setup ioctls.
>
> That is the next level detail Jike will figure out and discuss soon.
>
> yes, basic region info/access should be necessary. For interrupt, could
> you elaborate a bit what current interface is doing? If just about creating
> an eventfd for virtual interrupt injection, it applies to vgpu too.
>
> >
> > > IOMMU
> > >
> > > { in a new vfio_xxx.c }
> > >
> > > - allocate: struct device & IOMMU group
> >
> > It seems like the vgpu instance management would do this.
> >
> > > - map/unmap functions for vgpu
> > > - rb-tree to maintain iova/hpa mappings
> >
> > Yep, pretty much what type1 does now, but without mapping through the
> > IOMMU API. Essentially just a database of the current userspace
> > mappings that can be accessed for page pinning and IOVA->HPA
> > translation.
>
> The thought is to reuse iommu_type1.c, by abstracting several underlying
> operations and then put vgpu specific implementation in a vfio_vgpu.c (e.g.
> for map/unmap instead of using IOMMU API, an iova/hpa mapping is updated
> accordingly), etc.
>
> This file will also connect between VFIO and vendor specific vgpu driver,
> e.g. exposing interfaces to allow the latter querying iova<->hpa and also
> creating necessary VFIO structures like aforementioned device/IOMMUas...
>
> >
> > > - interacts with kvmgt.c
> > >
> > >
> > > vgpu instance management
> > >
> > > { in i915 }
> > >
> > > - path, create/destroy
> > >
> >
> > Yes, and since you're creating and destroying the vgpu here, this is
> > where I'd expect a struct device to be created and added to an IOMMU
> > group. The lifecycle management should really include links between
> > the vGPU and physical GPU, which would be much, much easier to do with
> > struct devices create here rather than at the point where we start
> > doing vfio "stuff".
>
> It's invoked here, but expecting the function exposed by vfio_vgpu.c. It's
> not good to touch vfio internal structures from another module (such as
> i915.ko)
>
> >
> > Nvidia has also been looking at this and has some ideas how we might
> > standardize on some of the interfaces and create a vgpu framework to
> > help share code between vendors and hopefully make a more consistent
> > userspace interface for libvirt as well. I'll let Neo provide some
> > details. Thanks,
> >
>
> Nice to know that. Neo, please share your thought here.
Hi Alex, Kevin and Jike,
Thanks for adding me to this technical discussion, a great opportunity
for us to design together which can bring both Intel and NVIDIA vGPU solution to
KVM platform.
Instead of directly jumping to the proposal that we have been working on
recently for NVIDIA vGPU on KVM, I think it is better for me to put out couple
quick comments / thoughts regarding the existing discussions on this thread as
fundamentally I think we are solving the same problem, DMA, interrupt and MMIO.
Then we can look at what we have, hopefully we can reach some consensus soon.
> Yes, and since you're creating and destroying the vgpu here, this is
> where I'd expect a struct device to be created and added to an IOMMU
> group. The lifecycle management should really include links between
> the vGPU and physical GPU, which would be much, much easier to do with
> struct devices create here rather than at the point where we start
> doing vfio "stuff".
Infact to keep vfio-vgpu to be more generic, vgpu device creation and management
can be centralized and done in vfio-vgpu. That also include adding to IOMMU
group and VFIO group.
Graphics driver can register with vfio-vgpu to get management and emulation call
backs to graphics driver.
We already have struct vgpu_device in our proposal that keeps pointer to
physical device.
> - vfio_pci will inject an IRQ to guest only when physical IRQ
> generated; whereas vfio_vgpu may inject an IRQ for emulation
> purpose. Anyway they can share the same injection interface;
eventfd to inject the interrupt is known to vfio-vgpu, that fd should be
available to graphics driver so that graphics driver can inject interrupts
directly when physical device triggers interrupt.
Here is the proposal we have, please review.
Please note the patches we have put out here is mainly for POC purpose to
verify our understanding also can serve the purpose to reduce confusions and
speed up
our design, although we are very happy to refine that to something eventually
can be used for both parties and upstreamed.
Linux vGPU kernel design
==================================================================================
Here we are proposing a generic Linux kernel module based on VFIO framework
which allows different GPU vendors to plugin and provide their GPU
virtualization
solution on KVM, the benefits of having such generic kernel module are:
1) Reuse QEMU VFIO driver, supporting VFIO UAPI
2) GPU HW agnostic management API for upper layer software such as libvirt
3) No duplicated VFIO kernel logic reimplemented by different GPU driver vendor
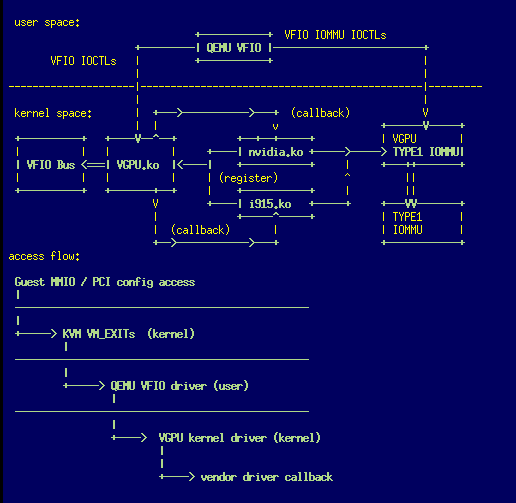
0. High level overview
==================================================================================
user space:
+-----------+ VFIO IOMMU IOCTLs
+---------| QEMU VFIO |-------------------------+
VFIO IOCTLs | +-----------+ |
| |
---------------------|-----------------------------------------------|---------
| |
kernel space: | +--->----------->---+ (callback) V
| | v +------V-----+
+----------+ +----V--^--+ +--+--+-----+ | VGPU |
| | | | +----| nvidia.ko +----->-----> TYPE1 IOMMU|
| VFIO Bus <===| VGPU.ko |<----| +-----------+ | +---++-------+
| | | | | (register) ^ ||
+----------+ +-------+--+ | +-----------+ | ||
V +----| i915.ko +-----+ +---VV-------+
| +-----^-----+ | TYPE1 |
| (callback) | | IOMMU |
+-->------------>---+ +------------+
access flow:
Guest MMIO / PCI config access
|
-------------------------------------------------
|
+-----> KVM VM_EXITs (kernel)
|
-------------------------------------------------
|
+-----> QEMU VFIO driver (user)
|
-------------------------------------------------
|
+----> VGPU kernel driver (kernel)
|
|
+----> vendor driver callback
1. VGPU management interface
==================================================================================
This is the interface allows upper layer software (mostly libvirt) to query and
configure virtual GPU device in a HW agnostic fashion. Also, this management
interface has provided flexibility to underlying GPU vendor to support virtual
device hotplug, multiple virtual devices per VM, multiple virtual devices from
different physical devices, etc.
1.1 Under per-physical device sysfs:
----------------------------------------------------------------------------------
vgpu_supported_types - RO, list the current supported virtual GPU types and its
VGPU_ID. VGPU_ID - a vGPU type identifier returned from reads of
"vgpu_supported_types".
vgpu_create - WO, input syntax <VM_UUID:idx:VGPU_ID>, create a virtual
gpu device on a target physical GPU. idx: virtual device index inside a VM
vgpu_destroy - WO, input syntax <VM_UUID:idx>, destroy a virtual gpu device on a
target physical GPU
1.3 Under vgpu class sysfs:
----------------------------------------------------------------------------------
vgpu_start - WO, input syntax <VM_UUID>, this will trigger the registration
interface to notify the GPU vendor driver to commit virtual GPU resource for
this target VM.
Also, the vgpu_start function is a synchronized call, the successful return of
this call will indicate all the requested vGPU resource has been fully
committed, the VMM should continue.
vgpu_shutdown - WO, input syntax <VM_UUID>, this will trigger the registration
interface to notify the GPU vendor driver to release virtual GPU resource of
this target VM.
1.4 Virtual device Hotplug
----------------------------------------------------------------------------------
To support virtual device hotplug, <vgpu_create> and <vgpu_destroy> can be
accessed during VM runtime, and the corresponding registration callback will be
invoked to allow GPU vendor support hotplug.
To support hotplug, vendor driver would take necessary action to handle the
situation when a vgpu_create is done on a VM_UUID after vgpu_start, and that
implies both create and start for that vgpu device.
Same, vgpu_destroy implies a vgpu_shudown on a running VM only if vendor driver
supports vgpu hotplug.
If hotplug is not supported and VM is still running, vendor driver can return
error code to indicate not supported.
Separate create from start gives flixibility to have:
- multiple vgpu instances for single VM and
- hotplug feature.
2. GPU driver vendor registration interface
==================================================================================
2.1 Registration interface definition (include/linux/vgpu.h)
----------------------------------------------------------------------------------
extern int vgpu_register_device(struct pci_dev *dev,
const struct gpu_device_ops *ops);
extern void vgpu_unregister_device(struct pci_dev *dev);
/**
* struct gpu_device_ops - Structure to be registered for each physical GPU to
* register the device to vgpu module.
*
* @owner: The module owner.
* @vgpu_supported_config: Called to get information about supported vgpu
* types.
* @dev : pci device structure of physical GPU.
* @config: should return string listing supported
* config
* Returns integer: success (0) or error (< 0)
* @vgpu_create: Called to allocate basic resouces in graphics
* driver for a particular vgpu.
* @dev: physical pci device structure on which
* vgpu
* should be created
* @vm_uuid: VM's uuid for which VM it is intended
* to
* @instance: vgpu instance in that VM
* @vgpu_id: This represents the type of vgpu to be
* created
* Returns integer: success (0) or error (< 0)
* @vgpu_destroy: Called to free resources in graphics driver for
* a vgpu instance of that VM.
* @dev: physical pci device structure to which
* this vgpu points to.
* @vm_uuid: VM's uuid for which the vgpu belongs
* to.
* @instance: vgpu instance in that VM
* Returns integer: success (0) or error (< 0)
* If VM is running and vgpu_destroy is called
that
* means the vGPU is being hotunpluged. Return
* error
* if VM is running and graphics driver doesn't
* support vgpu hotplug.
* @vgpu_start: Called to do initiate vGPU initialization
* process in graphics driver when VM boots before
* qemu starts.
* @vm_uuid: VM's UUID which is booting.
* Returns integer: success (0) or error (< 0)
* @vgpu_shutdown: Called to teardown vGPU related resources for
* the VM
* @vm_uuid: VM's UUID which is shutting down .
* Returns integer: success (0) or error (< 0)
* @read: Read emulation callback
* @vdev: vgpu device structure
* @buf: read buffer
* @count: number bytes to read
* @address_space: specifies for which address
* space
* the request is: pci_config_space, IO register
* space or MMIO space.
* Retuns number on bytes read on success or error.
* @write: Write emulation callback
* @vdev: vgpu device structure
* @buf: write buffer
* @count: number bytes to be written
* @address_space: specifies for which address
* space
* the request is: pci_config_space, IO register
* space or MMIO space.
* Retuns number on bytes written on success or
* error.
* @vgpu_set_irqs: Called to send about interrupts configuration
* information that qemu set.
* @vdev: vgpu device structure
* @flags, index, start, count and *data : same as
* that of struct vfio_irq_set of
* VFIO_DEVICE_SET_IRQS API.
*
* Physical GPU that support vGPU should be register with vgpu module with
* gpu_device_ops structure.
*/
struct gpu_device_ops {
struct module *owner;
int (*vgpu_supported_config)(struct pci_dev *dev, char *config);
int (*vgpu_create)(struct pci_dev *dev, uuid_le vm_uuid,
uint32_t instance, uint32_t vgpu_id);
int (*vgpu_destroy)(struct pci_dev *dev, uuid_le vm_uuid,
uint32_t instance);
int (*vgpu_start)(uuid_le vm_uuid);
int (*vgpu_shutdown)(uuid_le vm_uuid);
ssize_t (*read) (struct vgpu_device *vdev, char *buf, size_t count,
uint32_t address_space, loff_t pos);
ssize_t (*write)(struct vgpu_device *vdev, char *buf, size_t count,
uint32_t address_space,loff_t pos);
int (*vgpu_set_irqs)(struct vgpu_device *vdev, uint32_t flags,
unsigned index, unsigned start, unsigned count,
void *data);
};
2.2 Details for callbacks we haven't mentioned above.
---------------------------------------------------------------------------------
vgpu_supported_config: allows the vendor driver to specify the supported vGPU
type/configuration
vgpu_create : create a virtual GPU device, can be used for device
hotplug.
vgpu_destroy : destroy a virtual GPU device, can be used for device
hotplug.
vgpu_start : callback function to notify vendor driver vgpu device
come to live for a given virtual machine.
vgpu_shutdown : callback function to notify vendor driver
read : callback to vendor driver to handle virtual device config
space or MMIO read access
write : callback to vendor driver to handle virtual device config
space or MMIO write access
vgpu_set_irqs : callback to vendor driver to pass along the interrupt
information for the target virtual device, then vendor
driver can inject interrupt into virtual machine for this
device.
2.3 Potential additional virtual device configuration registration interface:
---------------------------------------------------------------------------------
callback function to describe the MMAP behavior of the virtual GPU
callback function to allow GPU vendor driver to provide PCI config space backing
memory.
3. VGPU TYPE1 IOMMU
==================================================================================
Here we are providing a TYPE1 IOMMU for vGPU which will basically keep track
the
<iova, hva, size, flag> and save the QEMU mm for later reference.
You can find the quick/ugly implementation in the attached patch file, which is
actually just a simple version Alex's type1 IOMMU without actual real
mapping when IOMMU_MAP_DMA / IOMMU_UNMAP_DMA is called.
We have thought about providing another vendor driver registration interface so
such tracking information will be sent to vendor driver and he will use the QEMU
mm to do the get_user_pages / remap_pfn_range when it is required. After doing a
quick implementation within our driver, I noticed following issues:
1) OS/VFIO logic into vendor driver which will be a maintenance issue.
2) Every driver vendor has to implement their own RB tree, instead of reusing
the common existing VFIO code (vfio_find/link/unlink_dma)
3) IOMMU_UNMAP_DMA is expecting to get "unmapped bytes" back to the caller/QEMU,
better not have anything inside a vendor driver that the VFIO caller immediately
depends on.
Based on the above consideration, we decide to implement the DMA tracking logic
within VGPU TYPE1 IOMMU code (ideally, this should be merged into current TYPE1
IOMMU code) and expose two symbols to outside for MMIO mapping and page
translation and pinning.
Also, with a mmap MMIO interface between virtual and physical, this allows
para-virtualized guest driver can access his virtual MMIO without taking a MMAP
fault hit, also we can support different MMIO size between virtual and physical
device.
int vgpu_map_virtual_bar
(
uint64_t virt_bar_addr,
uint64_t phys_bar_addr,
uint32_t len,
uint32_t flags
)
EXPORT_SYMBOL(vgpu_map_virtual_bar);
int vgpu_dma_do_translate(dma_addr_t *gfn_buffer, uint32_t count)
EXPORT_SYMBOL(vgpu_dma_do_translate);
Still a lot to be added and modified, such as supporting multiple VMs and
multiple virtual devices, tracking the mapped / pinned region within VGPU IOMMU
kernel driver, error handling, roll-back and locked memory size per user, etc.
4. Modules
==================================================================================
Two new modules are introduced: vfio_iommu_type1_vgpu.ko and vgpu.ko
vfio_iommu_type1_vgpu.ko - IOMMU TYPE1 driver supporting the IOMMU
TYPE1 v1 and v2 interface.
vgpu.ko - provide registration interface and virtual device
VFIO access.
5. QEMU note
==================================================================================
To allow us focus on the VGPU kernel driver prototyping, we have introduced a
new VFIO
class - vgpu inside QEMU, so we don't have to change the existing vfio/pci.c
file and
use it as a reference for our implementation. It is basically just a quick c & p
from vfio/pci.c to quickly meet our needs.
Once this proposal is finalized, we will move to vfio/pci.c instead of a new
class, and probably the only thing required is to have a new way to discover the
device.
6. Examples
==================================================================================
On this server, we have two NVIDIA M60 GPUs.
address@hidden ~]# lspci -d 10de:13f2
86:00.0 VGA compatible controller: NVIDIA Corporation Device 13f2 (rev a1)
87:00.0 VGA compatible controller: NVIDIA Corporation Device 13f2 (rev a1)
After nvidia.ko gets initialized, we can query the supported vGPU type by
accessing the "vgpu_supported_types" like following:
address@hidden ~]# cat /sys/bus/pci/devices/0000\:86\:00.0/vgpu_supported_types
11:GRID M60-0B
12:GRID M60-0Q
13:GRID M60-1B
14:GRID M60-1Q
15:GRID M60-2B
16:GRID M60-2Q
17:GRID M60-4Q
18:GRID M60-8Q
For example the VM_UUID is c0b26072-dd1b-4340-84fe-bf338c510818, and we would
like to create "GRID M60-4Q" VM on it.
echo "c0b26072-dd1b-4340-84fe-bf338c510818:0:17" >
/sys/bus/pci/devices/0000\:86\:00.0/vgpu_create
Note: the number 0 here is for vGPU device index. So far the change is not
tested
for multiple vgpu devices yet, but we will support it.
At this moment, if you query the "vgpu_supported_types" it will still show all
supported virtual GPU types as no virtual GPU resource is committed yet.
Starting VM:
echo "c0b26072-dd1b-4340-84fe-bf338c510818" > /sys/class/vgpu/vgpu_start
then, the supported vGPU type query will return:
address@hidden /home/cjia]$
> cat /sys/bus/pci/devices/0000\:86\:00.0/vgpu_supported_types
17:GRID M60-4Q
So vgpu_supported_config needs to be called whenever a new virtual device gets
created as the underlying HW might limit the supported types if there are
any existing VM runnings.
Then, VM gets shutdown, writes to /sys/class/vgpu/vgpu_shutdown will info the
GPU driver vendor to clean up resource.
Eventually, those virtual GPUs can be removed by writing to vgpu_destroy under
device sysfs.
7. What is not covered:
==================================================================================
7.1 QEMU console VNC
QEMU console VNC is not covered in this RFC as it is a pretty isolated module
and not impacting the basic vGPU functionality, also we already have a good
discussion about the new VFIO interface that Alex is going to introduce to
allow us
describe a region for VM surface.
8 Patches
==================================================================================
0001-Add-VGPU-VFIO-driver-class-support-in-QEMU.patch - against QEMU 2.5.0
0001-Add-VGPU-and-its-TYPE1-IOMMU-kernel-module-support.patch - against
4.4.0-rc5
Thanks,
Kirti and Neo
>
> Jike will provide next level API definitions based on KVMGT requirement.
> We can further refine it to match requirements of multi-vendors.
>
> Thanks
> Kevin
![]() 0001-Add-VGPU-and-its-TYPE1-IOMMU-kernel-module-support.patch
0001-Add-VGPU-and-its-TYPE1-IOMMU-kernel-module-support.patch
Description: Text document
![]() 0001-Add-VGPU-VFIO-driver-class-support-in-QEMU.patch
0001-Add-VGPU-VFIO-driver-class-support-in-QEMU.patch
Description: Text document
![]() vgpu_diagram.png
vgpu_diagram.png
Description: PNG image
| [Prev in Thread] | Current Thread | [Next in Thread] |
{kind=link}